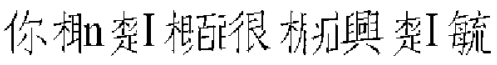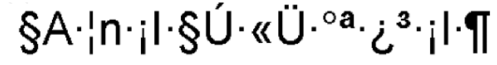|
Diese Seiten sollen in die Möglichkeiten einführen, die das Internet und seine Dienste für die China-Studien bieten. Einführung in die technischen Grundlagen Wie bringe ich meinem Computer Chinesisch bei? Newsgroups und Mailinglisten Suchmaschinen, Linkverzeichnisse und Virtual Libraries Zeitungslektüre am Bildschirm Chinesische Texte im Internet Bibliographieren am Bildschirm |
Einführung in die technischen Grundlagen der Verarbeitung asiatischer ZeichenDie Codierung asiatischer Zeichen - Babylon läßt grüßen...Der chinesischen Sprache liegt kein Alphabet zugrunde. Die Anzahl aller bekannten Zeichen und deren Variationen beträgt über 50.000 Stück. Der “Grundwortschatz” eines DOS-Rechners, auf dem nun auch Windows basiert, beträgt jedoch nur 256 Zeichen = 8 Bit = 1 Byte. Davon werden 96 für das Alphabet (ohne Umlaute) inkl. Satzzeichen, Währungszeichen etc. benötigt und 32 werden als interne Steuerzeichen verwendet. Diese 128 Zeichen sind immer gleich und werden ASCII ( American Standard Code for International Interchange) genannt, der 7 Bit Standard. Bleiben 128 Zeichen, die je nach Land für die Umlaute, akzentuierte Buchstaben, mathematische Symbole etc. verwendet werden können. Unter Windows wurde dann zum ANSI-Code übergegangen, der den Bereich ab dem Zeichen 127 vereinheitlichte. Sollen nun mehr als die zur Verfügung stehenden 256 Zeichen dargestellt werden, so muß zur 2-Byte-Codierung übergegangen werden. Diese stellt 65536 (2^16) mögliche Zeichen zur Verfügung. Platz genug für die “Schriften, die in den wichtigsten lebenden Sprachen benutzt werden”. Bei der 2-Byte-Codierung bilden immer 2 Zeichen aus dem Grundwortschatz von 256 die Grundlage für ein Neues, asiatisches Zeichen. Damit zwischen westlichen Alphabet und kodierten asiatischen Zeichen ein Trennlinie bestehen bleibt wurde vereinbart, daß das führende, also das erste, Byte in einer 2 Byte Kombination nicht aus den 127 Zeichen des ASCII Codes stammen kann. Damit blieben noch 32768 mögliche Kombinationen (2^15=128*256), ebenfalls noch genug für die asiatischen Zeichen des täglichen Gebrauchs.
Doch die Codierungen wurden nicht einheitlich entwickelt, jede Sprachgruppe entwickelte ihre eigene Codierung:
Und in jedem Code hat das gleiche asiatische Zeichen, daß von allen Ländern benutzt wird, einen unterschiedlichen Codepunkt. Beispiel: Das Zeichen
Die Lösung ist Unicode, dieser Code vereinheitlicht alle bisherigen Codepunkte auf einen Gemeinsamen.
Doch da Unicode bisher noch nicht sehr weit verbreitet ist, bleibt das Problem der verschiedenen Codierungen bestehen! Die im WWW publizierten Dokumente sind in allen bisher erwähnten Codierungen verfügbar. Wenn man Glück hat wird die verwendete codierung angegeben oder schon im HTML-Code vermerkt. Wenn man Pech hat bringt erst einiges probieren die gewünschte Darstellung der asiatischen Zeichen. Probleme, die aufgrund der Wahl des Codes oder durch die 2-Byte-Codierung entstehen könnenIm folgenden soll dargestellt werden, welche Probleme aufgrund der technischen Eigenarten der 2-Byte-Codierung auftreten können. Dies wird durch Grafiken erläutert. Wahl des falschen Codes führt zur falschen Darstellung von Zeichen:Diese Grafik zeigt wie chinesischer Text im GB-Code codiert dargestellt wird, wenn die Software auf die Darstellung von Big5-Codiertem Text eingestellt ist.
Durch den Zeilenumbruch werden die Zeichen der folgenden Zeile verstümmelt:Diese Grafik zeigt, wie chinesischer Text dargestellt wird, wenn der automatischen Zeilenumbruch ein 2-Byte-Zeichen an der falschen Stelle trennt.
Das Anzeigen von nichtdruckbaren Zeichen führt zur falschen Darstellung von chinesischen Zeichen:Hier ist die Schaltfläche dargestellt, die in Word für Windows die Anzeige nichtdruckbarer Zeichen aktiviert.
Dies ist der chinesische Text, so wie er aussehen sollte.
Dies ist der chinesische Text beeinflußt von der Anzeige der nichtdruckbaren Zeichen.
Hier ist der Grund für diese falsche Darstellung zu sehen. Diese Grafik stellt die Codierung dar ohne Einfluß eines chinesischen Programms. Die Leerstellen zwischen zwei Zeichen werden als kleiner Punkt dargestellt und das Absatzende als umgedrehtes “P”. Das Programm interpretiert nun aber diese Zeichen als Teil des Codes und stellt sie mit dem korrespondierenden chinesischen Zeichen des Codes dar. Aus ursprünglich 16 1-Byte-Zeichen werden durch die Anzeige von Leerstellen und Absatzende 25 1-Byte-Zeichen. Da führende 1-Byte-Zeichen aus dem ASCII-Zeichensatz nicht einem kodierten Zeichen entsprechenn können, werden sie dargestellt (das n und das I). Das A am Anfang ist noch korrekter Bestandteil eines 2-Byte-Zeichen! Umlaute werden verschluckt oder mit dem folgenden Buchstaben als ein 2-Byte-Zeichen dargestellt:Diese Grafik zeigt wie die deutschen Umlaute beeinflußt werden, wenn ein Programm alle auf dem Bildschirm dargestellten Zeichen interpretiert. Da die Umlaute nicht Bestandteil des ASCII-Codes sind, stellen sie für ein Programm ein führendes Byte eines 2-Byte-Zeichen dar. Dementsprechend wird das korrespondierende Zeichen der Code-Tabelle dargestellt. Ist dieser Codeplatz nicht belegt, führt dies zu einem “verschlucken” des Umlauts und des folgenden Zeichens. Ist der Codeplatz belegt wird das entsprechende Zeichen dargestellt.
|